When $b$ is unkown, we propose the following two methods to estimate it, and then estimate $\psi_i,\eta_i$ using $\hat b$.
The first is based on the joint covariance tensor, $T_{ijk} = \mathbb E[(f_i-\mu_i)(f_j-\mu_j)(f_k-\mu_k)]$, whose off diagonal elements correspond to a rank-1 tensor: $$ T_{ijk}= -b(1-b^2)(\psi_i+\eta_i-1) (\psi_j+\eta_j-1)(\psi_k+\eta_k-1)$$ Note that the vectors constructing $r_{ij}$ and $T_{ijk}$ are both proportional to $(\psi_i+\eta_i-1)$. In [1] , we use this observation to construct an estimate for $b$. We refer to this method as the 'tensor method'.
The second approach to estimate $b$ is based on the log-likelihood of our data: $$ \log\bigg( \prod_{j=1}^n \Pr(Z_{1j}, \ldots, Z_{mj}\bigg) = \sum_{j=1}^n \log\Pr(Z_{1j}, \ldots, Z_{mj})$$ Note that the likelihood is a function of $2m+1$ variables: $\{\psi_i\}_{i=1}^m$,$\{\eta_i\}_{i=1}^m$ and $b$. However, every guess for $b$ yields corresponding guesses for the remaining variables. We can therefore scan over $b \in [-1+\delta, 1-\delta]$, where $\delta>0$ corresponds to an a-priori bound on the class imbalance, and find the value which maximizes the log likelihood function. We denote this as the 'restricted likelihood' method.
4. Code
A matlab implementation of our unsupervised methods can be found here.
The file contains the following functions:
-
function b_hat = estimate_class_imbalance_tensor(Z,delta)
Input:
Z - $m \times n$ matrix containing the binary ($-1$ or $1$) predictions of $m$ classifiers over $n$ independent instances.
delta - the class imbalance estimation will be bounded away from $-1$ and $1$ by $\delta$.
Output:
b_hat - the estimate for the class imbalance by the tensor approach. b_hat = estimate_class_imbalance_restricted_likelihood(Z,delta)
Similar to the previous function, except that the estimate is done by the restricted likelihood approach.[V_hat,psi_hat,eta_hat] = estimate_ensemble_parameters(Z,b)
Input:
Z - $m \times n$ prediction matrix.
b - class imbalance (exact or estimated).
Output:
V_hat - first eigenvector of the covariance matrix $R$.
psi_hat - $m \times 1$ vector of estimated sensitivities.
eta_hat - $m \times 1$ vector of estimated specificities.
Additional routines (some required by the procedures above):
function [y,Z] = generate_prediction_matrix(m,n,b,psi,eta) - generates a random vector of true lablels y, and a random prediction matrix $Z$.
function R = estimate_rank_1_matrix(Q) - receives a $m \times m$ matrix and estimates its diagonal values, by assuming that the matrix is (or close to) rank 1.
function T = compute_classifier_3D_tensor(Z) - receives the prediction matrix $Z$ and returns the sample covariance tensor.
function alpha = estimate_alpha(V,T) - estimates the value of $\alpha(b)$, used by the tensor method to estimate $b$.
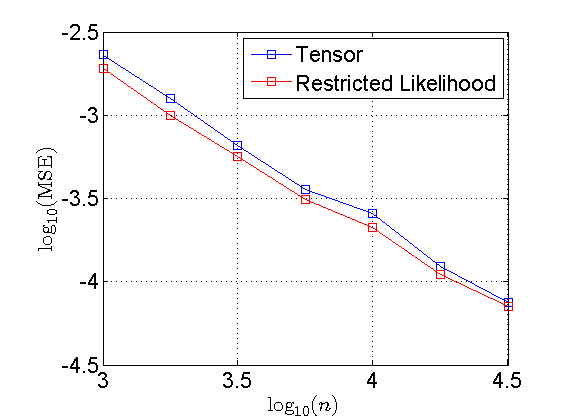
We also provide a demo code which generates synthetic random data and reproduces the following figure from [1] . This figure shows the mean square error
$\mathbb{E}[(\hat b-b)^2]$ in estimating the class imbalance, vs. the number of instances over a log-log scale, of the two methods described above. As seen from the figure,
on simulated data the restricted likelihood approach is more accurate than the tensor-based one.
5. References
- A. Jaffe, B. Nadler, Y. Kluger, Estimating the accuracies of multiple classifiers without labeled data , AISTATS-2015.
-
F. Parisi, F. Strino, B. Nadler, Y. Kluger, Ranking and Combining Multiple predictors without labeled data Proceedings of the National Academy of Sciences, vol. 111(4), 1253-1258, 2014.
L. I. Kuncheva, Combining pattern classifiers: methods and algorithms. John Wiley & Sons, 2004.
T. G. Dietterich, Ensemble Methods in Machine Learning. Multiple classifier systems. Springer Berlin Heidelberg, 2000. 1-15.
A. P. Dawid and A. M. Skene, Maximum likelihood estimation of observer error-rates using the EM algorith. Journal of the Royal Statistical Society, 1979.
V.C. Raykar, Y. Shipeng, L.H. Zhao, G.H. Valdez, C. Florin, L. Bogoni, and Moy L, Learning from crowds. Journal of Machine Learning Research, 2010.
J. Whitehill, P. Ruvolo, T. Wu, J Bergsma, and J.R. Movellan, Whose vote should count more: Optimal integration of labels from labelers of unknown expertise. In Advances in Neural Information Processing Systems 22, 2009.
P. Welinder, S. Branson, S. Belongie, and P. Perona, The multidimensional wisdom of crowds. In Advances in Neural Information Processing Systems 23, 2010.
P. Donmez, G. Lebanon, and K. Balasubramanian, Unsupervised Supervised Learning I: Estimating Classification and Regression Errors without Labels. The Journal of Machine Learning Research 11 (2010).
Y. Freund and Y. Mansour, Estimating a mixture of two product distributions. In Proceedings of the 12th Annual Conference on Computational Learning Theory,1999.
A. Anandkumar, D. Hsu, and S.M. Kakade, A method of moments for mixture models and hidden Markov models. In Conference on Learning Theory, 2012.
Y. Zhang, X. Chen, D. Zhou, and M.I. Jordan, Spectral methods meet EM: A provably optimal algorithm for crowdsourcing. In Advances in Neural Information Processing Systems 27, 2014.