
The LTR videos
were generated from these HTR videos by blurring and sub-sampling them in time
by a factor of 8 (by averaging every 8 frames). This is equivalent to a 'slower' video
camera recording the same dynamic scene, with full inter-frame exposure-time, at 1/8
framerate (30 fps).
These LTR videos were fed as inputs to the different algorithms.
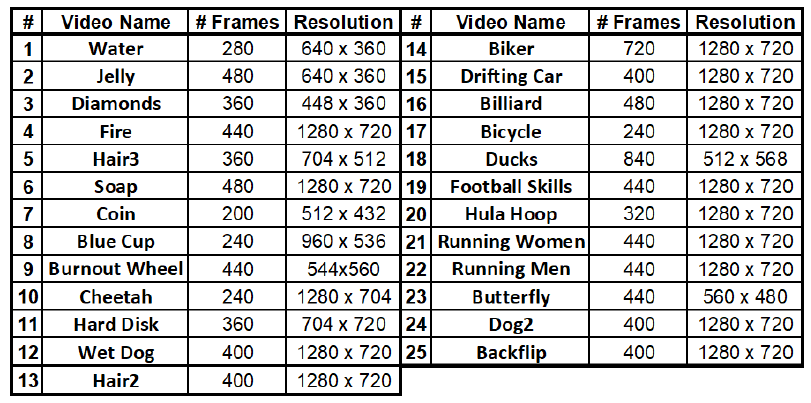
The dataset is split into two groups:
(i) Videos 1-13 are extremely challenging,
not only with severe motion blur, but also with severe motion aliasing and/or complex
highly non-rigid motions (e.g., splashing water, flickering fire, etc.);
(ii) Videos 14-25 are less challenging, still with sever motion blur, but mostly rigid motions.
This was done in order to highlight the type of videos that benefit the most from Internal-Learning.
| # | Video Name | # Frames | Resolution | # | Video Name | # Frames | Resolution | |
| 1 | Water | 280 | 640x360 | 14 | Biker | 720 | 1280x720 | |
| 2 | Jelly | 480 | 640x360 | 15 | Drifting car | 400 | 1280x720 | |
| 3 | Diamonds | 360 | 448x360 | 16 | Billiard | 480 | 1280x720 | |
| 4 | Fire | 440 | 1280x720 | 17 | Bicycle | 240 | 1280x720 | |
| 5 | Hair 3 | 360 | 704x512 | 18 | Ducks | 840 | 512x568 | |
| 6 | Soap | 480 | 1280x720 | 19 | Skills | 440 | 1280x720 | |
| 7 | Coin | 200 | 512x432 | 20 | Hula Hoop | 320 | 1280x720 | |
| 8 | Blue cup | 240 | 960x536 | 21 | Running women | 440 | 1280x720 | |
| 9 | Burnout wheel | 440 | 544x560 | 22 | Running men | 440 | 1280x720 | |
| 10 | Cheetah | 240 | 1280x704 | 23 | Butterfly | 440 | 560x480 | |
| 11 | hard disk | 360 | 704x720 | 24 | Dog | 400 | 1280x720 | |
| 12 | Wet dog | 400 | 1280x720 | 25 | Backflip | 400 | 1280x720 | |
| 13 | Hair 2 | 400 | 1280x720 |