This site presents the paper "Similarity by Composition" (NIPS 2006).
Presentation (ppt)
We propose a new approach for measuring similarity between two signals, which is applicable to many machine learning tasks, and to many signal types. We say that a signal S1 is “similar” to a signal S2 if it is “easy” to compose S1 from few large contiguous chunks of S2. Obviously, if we use small enough pieces, then any signal can be composed of any other. Therefore, the larger those pieces are, the more similar S1 is to S2. This induces a local similarity score at every point in the signal, based on the size of its supported surrounding region. These local scores can in turn be accumulated in a principled information-theoretic way into a global similarity score of the entire S1 to S2. “Similarity by Composition” can be applied between pairs of signals, between groups of signals, and also
between different portions of the same signal. It can therefore be employed in a wide variety of machine learning problems (clustering, classification, retrieval, segmentation, attention, saliency, labelling, etc.), and can be applied to a wide range of signal types (images, video, audio, biological data, etc.) We show a few such examples.|
|
Identify points with low LES scores as salient / irregular.
|
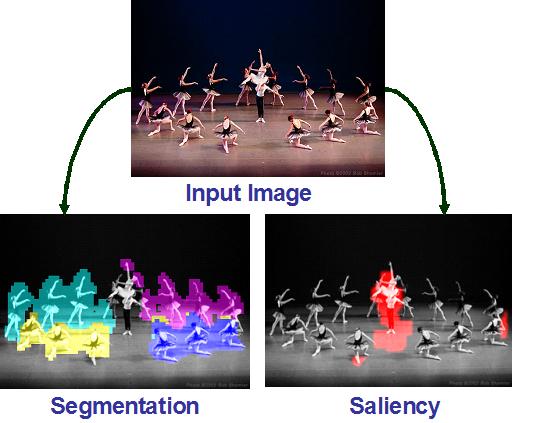
Detecting Saliency (no reference) |
|
|
Detecting Saliency (no reference) |
For applications to detecting suspicious behaviors see |
|
Fabric Inspection (no reference) |
Input Detected Defects (in red) |
|
Wafer Inspection (no reference) |
Input Output Input Output |
|
Fruit Inspection (a single 'good' reference) |
|
Pixels sharing a maximal region have evidence that they are part of the same pattern and they should be segmented together.
Using the LES scores of the maximal regions we build an affinity matrix of all point in the signal and use standard spectral clustering to segment the signal and extract meaningful patterns.
|
Segmentation of an image |
|
Action Database
example sequences, taken from [Blank et al, ICCV 2005].
The complete database can be found
here.
 |
 |
 |
We have used the
GES similarity score using a leave-one-out nearest neighbor classification.
97.5% of the classifications were correct.
Moreover, we were able to classify correctly much more complex queries, using the same database:
 |
 |
We have used a
database of a five-word sentence repeated 3 times by 31 speakers (overall 93
sequences).
We have use the GES similarity score using a leave-one-out nearest neighbor
retrieval.
97% of the retrieved speakers we correct.