
|

|

|

|

|
|

|

|

|
 
|

|
|
|
“Easy to compose”: Few large “puzzle pieces” |
 
|
|
“Hard to compose”: Many small “puzzle pieces” |
 
|
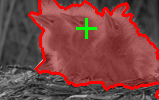
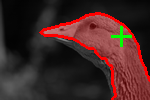
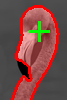
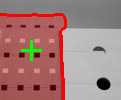
| Input Image | User selected point (green) and the recovered segmentation (red) | Recovered figure-ground segmentation |

|

|


|

|

|


|

|


|
|

|

|


|

|

|


|

|


|
|

|

|


|

|
|


|

|

|


|

|

|


|

|

|


|

|

|


|

|


|
|

|


|
|

|

|


|

|

|


|

|

|


|

|

|


|

|

|


|

|

|


|

|
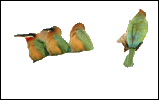

|
|

|

|


|

|


|
|

|

|


|

|

|


|

|

|


|

|

|


|

|


|
|

|

|


|

|


|
|

|


|
|

|
|


|

|

|


|

|

|


|

|

|


|

|

|


|

|

|

|

|

|


|

|

|


|

|

|


|

|

|


|

|

|


|

|
|


|

|

|


|

|

|


|

|

|


|

|

|


|

|

|
|

|


|
|

|


|
|

|

|


|

|

|

|

|

|


|

|


|
|

|

|


|

|

|


|

|


|
|

|

|


|

|


|
|

|

|


|

|

|


|

|

|


|

|

|


|

|
|

|

|
|


|

|


|
| Input Image pair | User selected point-of-interest | Recovered figure-ground segmentation |

 |

 |

 |

 |

 |

 |

 |

 |

 |

 |

 |

 |
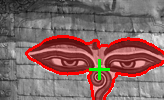
| Input image | Example images | point-of-interest | Recovered figure-ground segmentation |

|




|

|


|