Ablation Study
Why train a Deep linear generator ?

We compared kernel estimations of a single-layer-linear generator with our deep linear network. Notice the visual accuracy of our generator, while quantitatively outperforming by 3.8dB and 1.6dB for X2 and X4 scale factors on our DIV2KRK dataset.
Kernel Constraints Importance

To analyze the importance of each kernel constraint, we discard each constraint independently (and all together) and compare the estimation with and without it. Notice the estimations are similar but the constraint in necessary for higher accuracy. On the top row is the average PSNR over DIV2KRK dataset. The constraints add an average of 0.9dB.
Statistical Significance
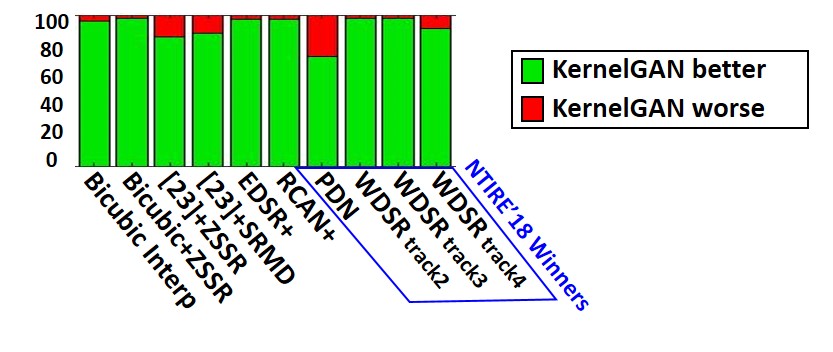
The plot provides statistical evidence for superiority of our method. In addition to the reported average PSNR on the whole DIV2KRK, we provide an image-wise comparison of our method to all others. Green is for images our method out-performed the one noted in the X-axis, while in red is vise-versa. Note that our method outperforms all other both by the average PSNR and in the number of images it enhances better.
Bicubic Estimations

Regarding the non-blind-super-resolution task (assuming the bicubic kernel), we ran KernelGAN on images downscaled bicubically. Notice the similarity of the estimation to the correct bicubic kernel.